There is a new Pennsylvania poll released today that has Trump leading Clinton 41.9% to 36.5% from a random sample of 1000 registered voters. The poll is released by a Canadian consulting firm that specializes in something like project management in the petroleum industry.
The poll is almost certainly fake, and without further information, it will not be included in my database of polls. It isn’t just the surprising results (Clinton has been leading Trump handily in PA for some time now) that leads me to exclude it. Rather it is what the “pollster” writes that flags this as a fake. The alternative is that the press release has been written by a rank amateur who has completely botched the description of the poll and, perhaps, the results.
At this point, I invite you to join me in some wonky fisking of the poll press release. Let’s start with the methods:
The survey is designed to use a scientific method to provide results which are as much as possible representative of the actual voter population with minimal distortion of results.
It uses “a scientific method”? Really! Don’t all polls? Real pollsters don’t say shit like this. Rather, they might mention using standard polling methods or some such thing. Most simply describe their methods without fanfare.
Adults 18 years of age and older registered voters residing in the state of Pennsylvania were contacted on landline numbers and interviewed in English using robo-call interviewers.
Nevermind that PA isn’t a state (it is a commonwealth). But “using robo-call interviewers” is rather informal for a description of methods. Inclusion of the word “interviewers” suggests sloppiness or ignorance of what a robo-poll is. “Using robo-call interviews”, perhaps. “Interviewers,” no.
Landline telephone numbers were randomly selected based upon a list of registered voters from throughout the state of Pennsylvania from reputable suppliers of random phone numbers to opinion research companies.
First, this is a very badly written sentence–a theme throughout the press release. But…”suppliers” in the plural? They needed more than one supplier of phone numbers for Registered voters? Who were they, and how did they get voter’s phone numbers to match up with the voter registration?
Samples generated are as close to truly random as possible.
No they weren’t. This sounds entirely like a non-statistician trying to sound technical. Nobody with real training in polling methods or statistics would make such an idiotic statement. First, nobody (particularly a real pollster) truly believes that samples in political polls are all that close to random, and (2) one could always find better (costlier) methods to draw samples that are closer to random.
The phone numbers were selected to ensure that each region was represented in proportion to its population.
Again, this seems suspect and amateurish in wording and from the lack of specifics. No regional breakdown was given in the results.
The questions asked during the Robo-call survey was kept extremely simple to minimize any distortion to the response due to: Framing of the questions, communication issues, distractions and the consequent impact on the interpretation and response.
Poorly written, bad grammar, and partially nonsensical. At this point, let me say that this could all be a function of a bad press release writer.
The questions asked were as follows: “Who will you vote for in November Presidential Elections?- Press 1 for Donald Trump. Press 2 for Hillary Clinton. Press 3 for Neither.”
That would be only one question, not “questions”. If this is truly the only question asked, then the poll results are fake, given that age and income questions must have been asked as well.
the sample was balanced based on the 2014 Pennsylvania Census
Only problem…there was no “2014 Pennsylvania Census”. There are population estimates for 2014 in PA, but these are based on the 2010 census. A knowledgeable writer might say, “based on 2014 population estimates for PA” or some such thing, but would never say “based on the 2014 PA census.”
This survey excluded the various counteracting variable factors to provide a more representative ground reality without complicating it with the said factors. These variable factors, inter alia consist of: In-State / Out-of-State migration, transients, people without landlines or cell phones, racial demographic representation at the polling booth. Another counter-acting set of variables is turnout: among young people, people who have never voted before, increased/decreased turnouts compared to previous elections. These factors are in a state of continual flux at this dynamic stage of the election process. It is not feasible to accurately include the impact of these factors without introducing unintended distortion in the outcome.
This is largely gobbledygook.
Note that both principals listed for this organization have Indian surnames, and this press release does have some elements of Indian English. I’ve spent a lot of time in S. Asia and working with Indian scientists and statisticians over the years, so I can say with some certainty that the errors, sloppiness, ambiguity and amateurishness of this press release are not a function of it being written in Indian English.
Results are statistically significant within ±7.1 percentage points, 19 times out of 20.
The “19 times out of 20” is an okay way of saying “at the 5% level”, but there is a problem with the margin of error (MOE) of 7.1%. The sample size is 1000, which makes 7.1% absurd for the MOE.
Pollsters find the 95% MOE as ±1.96*sqrt[p*(1-p)/N], where N is the sample size, p is the proportion for one candidate and (1 – p) for the other. Usually, pollsters find the maximum MOE by assuming there really is a tie (i.e. 0.5 for each candidate), so our equation becomes ±1.96*sqrt(0.25/N). Substituting in 1000 for N the MOE should be about ±3%, not ±7.1%.
Earlier in the press release was the statement:
According to CEPEX analysis, the error percentage is high due to the results obtained from just one day of polling. Subsequent polling would be required to reduce the error percentage.
This statement either betrays this as fraud or, perhaps, the press release writer is totally ignorant of statistical methods, sampling error and the like. The fact that it was only one day of polling is completely irrelevant. The MOE is simply based on the sample size (and the assumptions of a binomial process). It doesn’t matter whether 1000 people were asked in one hour or one week. On the other hand, this all might be an awkward way of saying that they could only squeeze in 1000 phone calls in a single day.
That’s it for methods, which can be criticized on other grounds as well (no cell phone subsample, no randomization of candidate order, registered instead of likely voters, etc.).
The results have some “funny” things in them as well.
They have 10 age categories. It is certainly possible that their polling robot would ask for direct age entry. So…okay, but what happened to 18-29 year-olds? It looks like the youngest age category starts at 30.
So much for their “random sample” of voters in Pennsylvania.
For income, they have an astonishing 15 categories. Political pollsters never ask for household income directly, only in rough categories. People are highly reluctant to give their income over the phone in a political survey. But pollsters do get reasonable compliance when asking about income in a small number of broad categories.
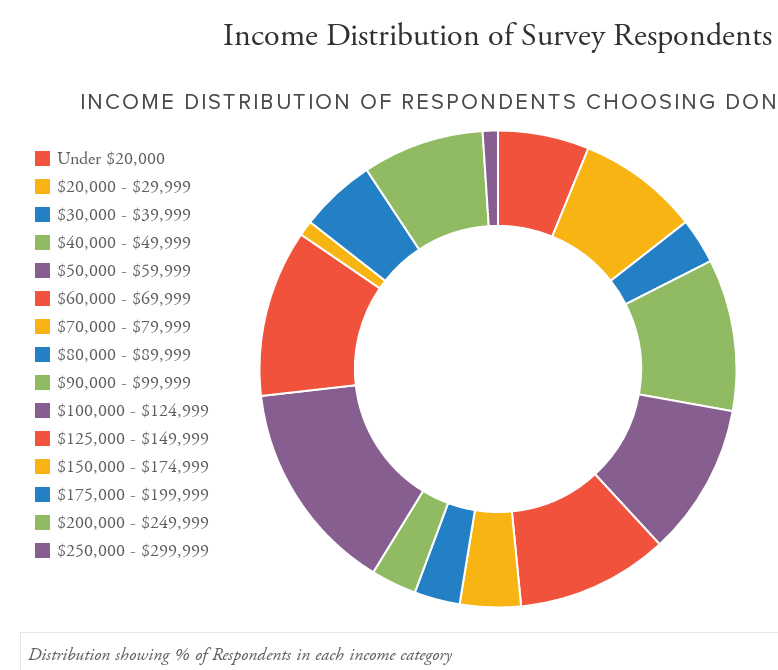
The fact is, no real election poll would ever ask about income in 15 categories. There are several reasons, particularly for robo-polls:
- It simply takes too long to read through all these categories
- There are only 10 digits + 2 symbols on the touchtone pad, so 12 categories would be the maximum. One key would be needed for a “read them again” response so that means 9 (or maybe 11 using symbols) categories could be the maximum realistic number of categories
- Too many categories reduce compliance because the income categories become too small. That is, as you increase the number of categories, it feels more and more like asking income directly.
The number of income categories alone suggests very strongly to me that this is a fake poll.
I took a quick look at the Waybackmachine for the URL, and it only has an archive from 2am today. I suppose it could be a brand new URL they moved to today, but given all the other issues”, it sure looks like a fake poll.
A couple of months ago, I was thinking about the incentives and disincentives for a campaign to set up a series of fake polls. If you believe that inertia can make a difference, then there are some good incentives for doing this.
This poll may be our first such specimen–if so, it is very badly done. In the future, they may be much more difficult to uncover.

Might be interesting to see if there are any commonalities between this product and some of the work Kellyanne Conaway did for Keep the Promise 1 up until last week.
The Trumpsters are lapping this stupid shit up like there’s no tomorrow. It’ll make his defeat all the sweeter.
Looks like Trump is outsourcing his polling to China. Maybe to the same outfit that makes his “Make America Great Again” hats.
If you’re gonna be all high and mighty to criticize someone’s GRAMMAR, you should at least not be a fuckwit and spell it incorrectly.
Your a looser!
@4 And yet, an ungrammatical criticism of somebody’s writing doesn’t magically invalidate that criticism.
Don Novello @ 4,
Okay…I’ll try to spell more things incorrectly to avoid being a fuckwit.
@6
Now that is funny.
Nice analysis.