Yesterday I took a break from my all-too-frequent analyses of the R-71 signature counts. I didn’t even look at the numbers until this morning. When I did look, a Spock-esque twitch afflicted my left eyebrow. “Curious”, I though. “But maybe it’s just a one-time fluke….”
The analysis of yesterday’s data showed the probability of NOT making the ballet increased from a nearly impossible 0.04% to an almost-interesting 0.91%. In fact, this slow increase in the probability of not qualifying has continued a trend begun after 13 August.
Well, if you like that result, hold onto your sou’wester, because today’s result will blow you away. I’ll present the results in three parts. First, the basic results for today, then we’ll explore the trends in the daily data dumps. Finally (and below the fold) we’ll look at the micro-level volume data to divine what this trend suggests.
Today’s R-71 data release has the signature count up to 79,195, (about 57.5% of the total). There have been 9,208 invalid signatures found, for a cumulative crude (non-duplicate-corrected) rejection rate of 11.63%.
The invalid signatures include 7,805 that were not found in the voting rolls, 703 duplicate signatures, and 700 signatures that mismatched the signature on file. There are also 38 signatures “pending”; I’ve ignored them in the analyses. The 703 duplicate signatures suggest a final duplication rate of about 1.90% for the petition. This continues the trend we’ve seen this week of the projected duplicate rate growing faster than the mathematical predictions under the assumption of random sampling.
Using the V2 estimator, the number of valid signatures is now expected to be 120,777 leaving a thin surplus of only 200 signatures over the 120,577 needed to qualify for the ballot. From the cumulative data to date, the overall rejection rate is projected to be 12.28%.
A Monte Carlo analyses consisting of 100,000 simulated petition samples suggests that the measure has an 80.48% probability of qualifying for the ballot, assuming the only “error” is statistical sampling error.
Here is the distribution of valid signatures relative to the number required to qualify.
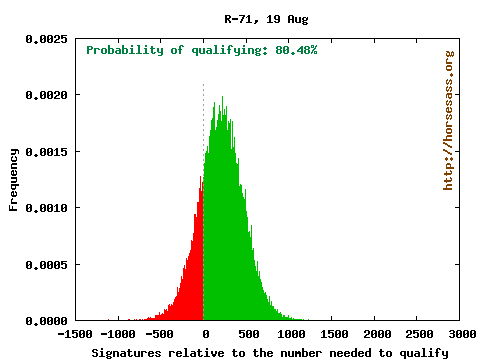
The red bars on the left show the times R-71 failed to qualify among the 100,000 simulations; green bars show the counts of signatures in which the measure qualified. Compare this to the results from just two days ago. Quite a difference!
Let’s examine the history since the SoS office started releasing accurate data a week and a half ago:
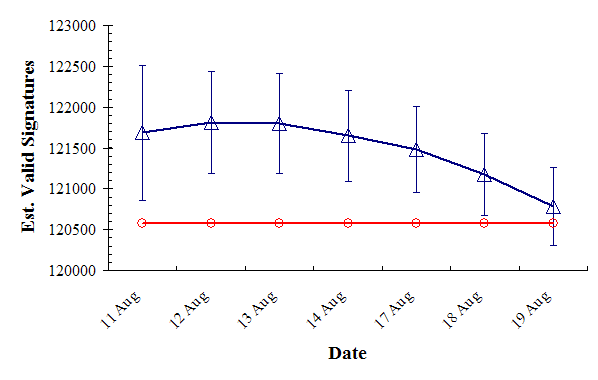
The red line shows the number of signatures needed to qualify, and the blue symbols show the daily projections of valid signatures, surrounded by 95% confidence intervals.
Clearly, since the 13th of August, the projected number of signatures has declined–and, as of today, declined more than we could expect by chance alone. Something is going on.
Tomorrow will be interesting…if the trend continues, success of the measure may dip below a probability of 50%.
The analyses I’ve done here are based on two assumptions: (1) that the signatures evaluated so far are just like signatures that remain to be evaluated, and (2) that the signature validation process is “stable” (the people validating signatures are not changing their standards over time). Today we see some pretty good evidence that one (or both) of these assumptions is (are) violated.
The supporters of R-71 will, no doubt, focus on the second assumption. If the measure fails, Secretary of State Sam Reed will likely take much abuse from fringe homophobes for “personally pushing a homosexual agenda.” To me, the simplest explanation is that the volumes being examined in serial order are chronologically correlated with the signature collection order. ( I don’t know if this is true; but, I cannot rule it out either.)
My thinking is that later-collected signatures (and therefore, later volumes) should have a higher duplication rate, just because there is an increasing chance with time early signers forgot whether or not they signed earlier. Additionally, with the last push of getting as many signatures as possible with an approaching deadline, it seems plausible that errors would increase. I’m thinking errors like collecting more out-of-state signatures, underage signatures, and signatures from people not active on the voter rolls.
Below the fold, I examine the fine-level data to see just what types of errors are increasing as the process proceeds. If you are still interested, click through…
Let’s first look at the trend in the projected number of signatures not found on the voter rolls (i.e. “missing” signatures). In these graphs, I look at volumes 201 through 361, and show the media and 95% confidence interval based on 10,000 Monte Carlo simulations. Volume 200 was completed in on the afternoon of 12th of August, and volume 361 was completed Wednesday afternoon:

Clearly there is a trend toward finding more missing signatures as the process continues. This could, conceivably, reflect reduced effort by signature checkers to find the signers in voter rolls. Alternatively, this might simply reflect the increasing sloppiness of signature collection over time.
Either way, the trend shows no signs of slowing down.
Here are the projected final number of duplicate signatures:
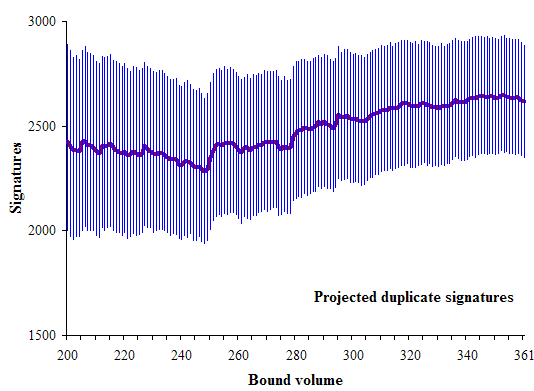
We see a positive trend from volume 245, but the trend stops increasing and shows signs of reversing itself at the end. It is difficult to know what to make of this trend.
Here are the projected number of mismatched signatures:
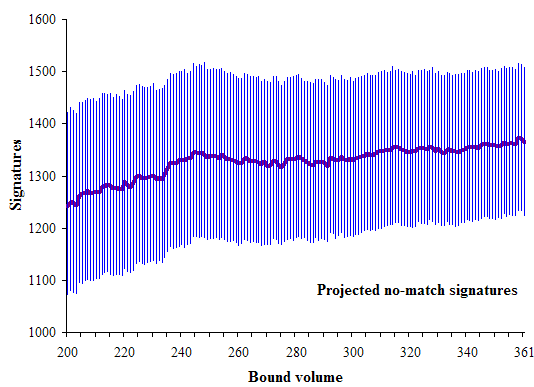
There is a whisper of a trend in mismatched signatures. But really, there is not much there.
Here is the projected total number of signatures over time:

This is a fine-scale version of the second figure in this post. It strongly suggests a linear declining trend since about volume 300 (and a more slowly declining trend before volume 300).
As I said, tomorrow’s data release will be very interesting. From today’s perspective, the results should be considered encouraging for supporters of the “all but marriage” law, because of trends that defy the underlying assumption of random sampling.

How many of the “no match” signatures are really invalid signatures? If R-71 fails to qualify by a few hundred votes or less, I can see its supporters filing a lawsuit over the matter. If they actually contact the “no match” voters, there is a pretty good chance that they will testify that they actually signed the petition. So they could prevail in court, and get R-71 qualified for the ballot.
If the court contest isn’t decided before the November ballots are printed, then the vote on R-71 will end up getting delayed until next year. So it might be better if the SoS approves R-71 for the ballot, instead of rejecting it on “no match” signatures that were actually signed by real voters and result in the court ordering R-71 to the ballot in next year’s election.
If I remember correctly – the Gregoire count allowed people called “no match” to contest that and prove their signatures.
And, that happened by court order via the Dems. Gregoire owes that good organizing gambit a great deal.
Two close friends worked feverishly on calling people and getting them to the courthouse to resign, the “no match” was corrected, thus votes counted.
Same thing should be possible here. This is a cliff hanger. And, the bigots seem a bit better prepared than usual …. too bad.
It seems to me that the error rate is edging up every day in a pattern that will almost surely result in failure to qualify.
I’m not a math expert, but every day the error rate seems to edge up a little more. And given the number of days it’ll take to complete the checking, the trend would seem to indicate failure.
The bigots are whining, here:
http://blogs.thenewstribune.co.....am_reed_of
“…So it might be better if the SoS approves R-71 for the ballot, instead of rejecting it on “no match” signatures that were actually signed by real voters…”
Well, the Secretary of State has no authority to accept R-71 for the ballot by ignoring the
“no match” signatures, simply because it might be expedient/efficient for him to do so.
The real questions seem to be: (a) to what lengths is the Secty of State office supposed to go to in order to establish that an apparant no-match was actually signed by a voter, and (b) who’s responsibility is it to provide the Secty of State with any additional information his office needs to allow it to accept an initiall “no-match” signature?
I’m not familiar with the laws and regulations under which the Secretary of State is performing this function. But it seems to me that the burden of qualifying a ballot should be different for an initiative petition, as opposed to a vote cast in a general election.
In the former case, the person or group sponsoring the initiative petition should have the burden of proving the validity of the signatures it solicited. To say otherwise would impose to great a burden on the Secretary of State’s office, as the dozens of initiative petition campaigns started each year could then claim that the Secretary of State’s office would have the obligation to accept all signatures, no matter how sloppy the effort in collecting them, unless it could clearly establish the signatures as invalid.
In the later case, the Secty of State’s office should have a greater obligation to determine actual voter intent, with a presumption that the ballot is valid. This situation is different because in a general election, the state controls the ballot mailing and collection process, thereby reducing the opportunities for improper ballots. After all, we don’t see over 12% of mail-in ballots rejected for one reason or another, as is within the range of probability in this initiative campaign.
1. All rejected signatures are double-checked by experienced senior “checkers”. They are using the latest database, which includes any registrants who registered through last month. I don’t see what more the Secretary can reasonably do. I also don’t see what the basis is for claiming or suspecting that there are valid names that are being called no-matches. That seems nothing more than your own imagination at work.
In fact, the review process is biased in favor of validation, because names that are matched by junior staff (perhaps erroneously) are not then double checked, but are simply added to the “accept” pile. Thus the rejected names get special attention and some are saved, while the accepted names are not given the same scrutiny.
This is being challenged and the Secretary shortly will be releasing the results of a sample double-check on 200 signatures initially accepted by junior staff. Any double-checking of the accepted signatures can only result in more of a shift against R71.
2. I was initially impressed by Daryl’s Monte Carlo analyses, but I think they are less than meets the eye. The error rate had been creeping up at about .3% per 10,000 signatures for some time now. That is not breaking news. Yet Daryl’s analysis is only now catching on.
His results are changing dramatically. He goes from saying on Monday that R71 is virtually certain to qualify, and fails in only 34 out of 100,000 simulations. Now just 2 days later, it has a 12% chance of qualifying, and he says that it will have a better than even chance if the error rate edges up by a comparable percentage just one more day. If your MC results can swing so wildly in just a few days, based on trend lines that are no different from those present last week, then I question what predictive value these models ever had.
@2 Gregoire owes even more to Rossi’s stupid lawyers. You see, although the GOPers were late in getting their signature validation drive off the ground, they did collect around 250 to 300 signature cards. The Democrats collected around 1,100 with a 70% validation rate; those ballots gave Gregoire her winning margin of 129 votes (ultimately, 133 votes after the election contest lawsuit). If the 70% validation rate held consistent for the signature cards collected by the GOPers, Rossi would have had at least 175 more votes, enough to win. However, Rossi’s lawyers refused to allow the Rossi campaign to submit those signatures because they believed it would undercut their argument to the court that the Democrats’ signature cards should be thrown out. They lost in court anyway, and their decision to withhold the signature cards their side had collected very likely cost Rossi the election. I’ve really gotta question whether Rossi’s lawyers were worth the $2 million the GOP paid them — they should’ve hired Gregoire’s lawyers, LOL!
@4 I think “howling at the moon” would be a more accurate description.
@8. Amen (irony intended).
The progressive community may have put itself in a bind by mobilizing to OPPOSE R-71.
If it makes the ballot, the gay-family-values option will be to APPROVE R-71 (thereby approving the legislative action on equal rights).
But voters approach ballot measures in general with a built-in bias in favor of “NO” … it takes work to get them to “YES”.
And we’ve spent months drumming the “DOWN WITH R-71” message into our most sympathetic voters, many of whom will proudly vote “NO” (thinking they are striking a blow for gay rights).
Of course if R-71 does make the ballot, and does pass, it will have 100 times the positive national impact as merely keeping it off the WA ballot would have.
@10: Strange that people are excited about this making the ballot. It explains why people dismiss statistical analysis when it shows it not making the ballot, but eagerly latch on if analysis shows that it will make it.
What would be “100 times” better than being on the defensive all the time is a marriage equality initiative. What would be “100 times” better is fighting on our terms and not trying to hold our ground. What would be “100 times” better is actual pride, joy and determination, not fear and trepidation.
The batches or volumes were rather randomly assembled, not in a chronological order by date of petition, nor by geographic region. Many of the volumes checked thus far are with petitions that were fully filled in with 20 names apiece.
Regarding the comments about that “no match” rejections, checkers have neither the manpower nor the authority to go contacting the voter to come in and fix the disrepancy or prove their signature. In this way, signature-verification is different for I&R than it is for a voter’s ballot.
@11 — Validation by the whole body politic of a major state would be 100 times better that an obscure technical victory against a clown-show signature-gathering effort.
@13: That’s the easy way out, isn’t it?
Don’t fight for your rights, just wait until you have to defend them. Ask the state to give them to you, religious right fights you, hope you win. Wash, rinse, repeat.
We have an initiative process, you know. We have these large equal rights groups that are supposedly fighting for us, but it seems more like a constant defensive stance that only gains ground when the government graciously allows us to do so. And when they do? Oh yeah, those rights they were wonderful and let us have? They won’t all be in effect for at least 5 years.
Instead, we sit and wait to defend ourselves. Maybe ERW could propose an equal rights initiative next year. And the next. And the next. And the next. And the next. They have the capital and staff to undertake such a simple measure that is typically the work of a couple of people and some volunteers.
Unless we’re actually wrong about all these rights things.
@ 14 – Fight smart. Fight to win.
Steven @ 6,
“I was initially impressed by Daryl’s Monte Carlo analyses, but I think they are less than meets the eye. The error rate had been creeping up at about .3% per 10,000 signatures for some time now. That is not breaking news. Yet Daryl’s analysis is only now catching on.”
As I have tried to make clear, the Monte Carlo analysis only accounts for sampling error, that is, the error reflecting that only a sample of the total petition has been evaluated. Furthermore, I have tried to be clear that there is an assumption of random sampling, and consistency over time in the validation process (the “stability” point mentioned above).
One reason I keep repeating the analysis is to look for evidence of departures from these assumptions. There is good evidence for that now, because the rate of finding invalid signatures is systematically shifting in a way inconsistent with the sampling error.
“His results are changing dramatically. He goes from saying on Monday that R71 is virtually certain to qualify, and fails in only 34 out of 100,000 simulations.”
In Monday’s post I cite the methods where I state:
The subsequent analyses showed that there were some trends in different types of error rates, but that:
That is still true…from volumes 70 through 210, the numbers were stable.
“Now just 2 days later, it has a 12% chance of qualifying, and he says that it will have a better than even chance if the error rate edges up by a comparable percentage just one more day.”
Based on the error rates observed yesterday, the measure has a 19.5%, not 12%, chance of failing.
My point is that if the systematic changes in invalid rates follow the trend observed this week, the measure will switch from “most likely succeed” to “most likely fail.”
“If your MC results can swing so wildly in just a few days, based on trend lines that are no different from those present last week, then I question what predictive value these models ever had.”
I think there are two disconnects here.
First, my aim has been to “project”, not to “predict”. In other words (and to use something of a sports analogy) I am using the score right NOW to project how the game should end if the scoring trend continues for the rest of the game. I’ve tried to be clear that the projected results don’t hold if the underlying invalid signature rates change.
Second, the entire point of this current analysis is to demonstrate that the trend lines really are different from what we saw last week. This is very clear when looking at the “missing” signatures this week and the “missing” signatures last week.
David Ammons @ 12,
“The batches or volumes were rather randomly assembled, not in a chronological order by date of petition, nor by geographic region. Many of the volumes checked thus far are with petitions that were fully filled in with 20 names apiece.”
Thanks for the comment. I have previously noted that the SoS FAQ states:
And I don’t doubt that. But social scientists and survey researchers are constantly hand-wringing over how random their random samples really are.
My intuition is that it would be a huge amount of work to truly randomize all the signature pages.
One test could be to select a couple of early volumes and a couple of later volumes. Then see if the dates (from the signature gatherers) cluster in obvious ways (as if you have nothing else to do).
@4
This quote from that article is priceless.
.
#6 and #12
First, it is not simple foolish conjecture. In a very like close ballot moment, here, we have a very close signature drive effort.
Both are the purvey of the voter and their intentions to vote or legislate via the petition to have a ballot contest on an issue.
In both cases there is no incentive for any registered voter to fuck up a signature match, no intended fraud. None. The match problem happens in the course of how people write their name, with all the changes involving age, illness, haste, etc. in the mix. None of the reasons seem nefarious to me. The match system in effect is run by rules and assumptions, but, the person IS registered and the match part is out of the signers control at this point.
It is the one place the bigots can get possible recourse with the courts and harvest valid signatures. And I suspect that will be a legal case if they fall short by just a few hundred signatures.
Call it – The Rectify No Match Open Door, court mandated, designed to be fair to signers who have been affirmed as real OK voters.
It won’t be business as usual if the count is so very close.
Yes a cliff hanger. And the poor Sec. of State Office is in the middle of the storm.
@Darryl:
I do appreciate your trying to explain the purposes and premises of the analysis. I freely admit that this is not my area of expertise.
However, I really don’t understand why you think the error rate trend is so different over the last two days. Here are the stats:
8/11 – 33,000 checked – Error rate of 10.42%
8/12 – 48,000 checked – 10.65%
8/13 – 50,000 checked – 10.68%
8/14 – 58,000 checked – 10.99%
8/17 – 65,000 checked – 11.03%
8/18 – 73,000 checked – 11.32%
8/19 – 80,0000 checked – 11.67%
(The number of names checked is rounded down to the nearest thousand.)
Anyway, to my novice eye, this shows pretty clearly that the error rate was deteriorating at a steady clip. The error rate has degraded more rapidly in the last 2 days, true, but the trend in place by last Friday (8/14) would show that R71 was in real trouble.
Only on 8/17 did it fail to move by a material amount following a substantial number of checks completed. On every other day, it moved in a trend line that would show R71 either failing to qualify outright, or in one scenario in which the 8/11-12 trend is extrapolated (.23% per 15,000 checked), qualifying by the skin of its teeth. Looking back on the trend since 8/11, I really cannot see how the MC projection could be for near-certain success.
Steven,
“Anyway, to my novice eye, this shows pretty clearly that the error rate was deteriorating at a steady clip. The error rate has degraded more rapidly in the last 2 days, true, but the trend in place by last Friday (8/14) would show that R71 was in real trouble.”
It isn’t this simple. Imagine if the ONLY reason for a signature to be invalid is because the voter isn’t registered. Then, if the signatures are a random sample of all signatures, and the rejection process is “stable”, then we would expect the rate to remain constant for whatever sample size we have examined. Right?
Now, suppose the ONLY source of error is duplicates. In that case, the error rate seems to go UP as the sample size increases. In fact the number of duplicates found increases as (almost) the square of the ratio of total signatures to the sampled signatures.
So…if duplicates were the only source of error, a random sample, with a “stable” inspection process, we would underestimate true error rate at small sample sizes and gradually increase with larger samples until we hit the true error rate when the full petition is completed.
The numbers you show above are a composite of those two distinct types of error rates. Here are the rates broken down by “fixed” and “duplicate” types:
Date … Dups .. Fixed .. Sum
11-Aug 0.39% 10.00% 10.39%
12-Aug 0.50% 10.10% 10.60%
13-Aug 0.52% 10.12% 10.65%
14-Aug 0.59% 10.26% 10.85%
17-Aug 0.72% 10.27% 10.99%
18-Aug 0.81% 10.46% 11.28%
19-Aug 0.89% 10.74% 11.63%
Now, once we eliminate the duplicate error rate increase (because that is supposed to go up with sample size) the remaining “fixed” error rate only increases 0.27% from the 11th to the 17th. That amount wasn’t enough to rule out chance.
Because there are these two types of error rates, I use both type of fixed error rates (“not found in voter roll” and “signature mismatch”) and the duplicate rate to compute the expected TOTAL error rate or, equivalently, the total number of valid signatures expected.
The second figure above shows this. (NOTE: You can convert total signatures into total acceptance rate by dividing by the number of signatures submitted–it only changes the label and number on the y-axis. Subtract the numbers from 100% and you get the total rejection rate. This doesn’t change the figure: the curve and confidence intervals look identical except that they are flipped upside-down.)
As you can see in the figure, from the 11th through the 17th the decline was small compared to the magnitude of the 95% confidence intervals. Hence, there is an absence of evidence for changes in the rates of rejection. (I.e. it could be sampling error alone).
The rate found last night, however, offeres strong evidence that there are real changes in the rate at which signatures are rejected.
You better read the latest SofS blog. It looks like they are pulling the football away from us again. It says “We currently are reviewing the pool of 7,805 ‘not found’ signers to date, and have indications that approximately 12 percent of those will change to registered voters.”
If I am reading this correctly, this reclassification is because the state database of registered voters is not up to date. Many people signed the referendum AND registered to vote at the same time, and those registrations are not yet in the state database. So, the daily tallies showing “the accepted and rejected totals as each bound volume completes the verification process” apparently have not really completed the verification process! What other unpleasant surprises are in store?
RIGGED! RIGGED! RIGGED! The election officials are RIGGING this election to get this anti-gay initiative on the ballot. How many times have they changed the process to benefit this anti-gay initiative?
Let’s review how election officials have RIGGED the process to benefit the anti-gay BIGOTS that support this awful initiative.
* Election officials LIED to the media, told them the error rate needs to be lower than 14%. In reality it needs to be lower than 12.43%.
* On day five this referendum was NOT going to make it on the ballot then suddenly master fixers came in and “readjusted” the numbers by more than 19% thereby putting this referendum back in play. Gay people raised concerns about the process and guess what the election officials did? Looked at the same rejected signatures again. And you know what the rejected signature percent went down another 10%. Here we have the same rejected signatures looked at at least FOUR times with FOUR massively different numbers
* The rejected signatures of the first 33,000+ are checked at least FOUR times, twice by junior checkers and twice by master checkers. While the accepted signatures, which accounted for 89% of the signatures, are only counted ONCE.
* Husand and wife checkers, Roger and Valerie gave names to outside people to confirm they signed the petition which is ILLEGAL.
* Rejected signatures are NOW going to get ANOTHER look because according to the secretary of state spokesperson voter registration wasn’t “updated.” Election officials say that 12% of those already rejected will put in the accepted pile.
* David Ammons told people concerned with the lopsided checking of the signatures basically gay people ain’t worth looking at the accepted signatures again. That election officials would only take a look at the already rejected ones.
WHY DON’T THESE ELECTION OFFICIALS JUST SAY THEY ARE RIGGING THE ELECTION?