How did the pollsters do for the 2016 election? That is a big and complicated question, because there are many different types and levels of polling done. In this post, I’ll look at the national polling in the Clinton—Trump race.
If my Twitter feed is any indication, the media seems hell-bent on the meme that “the polling was terrible” or “this is the end of polling.” But, as I show below, it wasn’t completely terrible for the national polling.
Yesterday, I heard a story on KUOW (I don’t remember the show, but perhaps All Things Considered or Here & Now) about the national polls. The story had things exactly wrong. They interviewed the director of the LA Times/USC poll (you know, the one that consistently had Trump leading Clinton), introducing it as “the one that got it right.” In fact, the LA Times/USC poll was the one that got it wrong.
Remember, national polls only tell us about the popular vote. And, as of this morning, Clinton leads in the popular vote. The LA Times/USC poll does use very interesting methods, asking their internet panel of respondents the probability of voting for each candidate. That is very cool (except for the internet panel part). But ultimately something about their poll led them to, almost uniquely, pick the wrong winner.
There are other criteria besides picking the right/wrong winner that are useful for evaluating the polls. A natural criterion is to ask which poll gets the percentages closest. That is what I have done. I’ve taken the national polling data as posted by Real Clear Politics and statistically evaluated “goodness of fit” between the poll result and the actual election outcome (as of this morning). The test I use is call a G-test of Goodness of Fit.
First I begin with the polls that did 2-way Clinton–Trump match-ups. Here are the polls from 31 Oct on, sorted newest to oldest (click for a larger image):
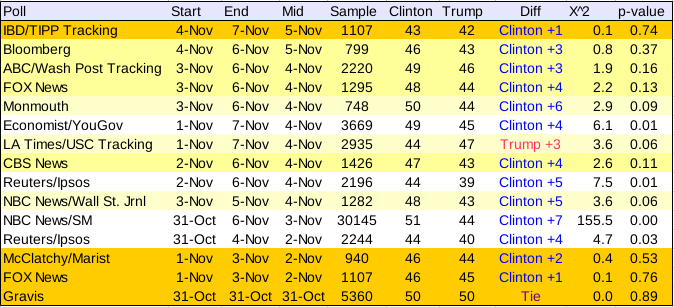
The “fit” of the poll is better for smaller numbers in the X^2 column, and the last column gives, essentially, the probability of observing deviations from the actual outcome at least this large given the sample size, assuming the poll was a true reflection of the outcome. I’ve highlighted the best fitting with darker colors (orange). The shades of yellow denote other polls that do not differ significantly. The worst fitting, those that differ significantly from the results, are shown in white.
The best polls are the four highlighted in orange, in order: The Gravis poll taken on 31 October, the FOX News poll taken from 1-3 Nov, IBD/TIPP Tracking poll taken 4-7 Nov, and the McClatchy poll taken 1-3 Nov. Odd that the three oldest polls are the closest.
The worst poll, by far, was the NBC News/Survey Monkey online tracking poll. This poll was way too optimistic for Clinton.
The LA Times/USC poll was middling. There is only a 6% probability of observing results this bad by chance. And, of course, the poll got the wrong winner.
But we see, using 4-way races, most of the national polls were, statistically, in the ball park. Ten of 14 weren’t had outcomes that were not statistically different from the actual election.
Here is the polling for the 4-way race. The extra two categories (Johnson and Stein) provides for more ways a poll can “deviate” from the observed election results, so the polls don’t fit as well overall. Many polls are heavily penalized for doing a lousy job in the Johnson or Stein percentages, even if the Trump and Clinton percentages are okay.
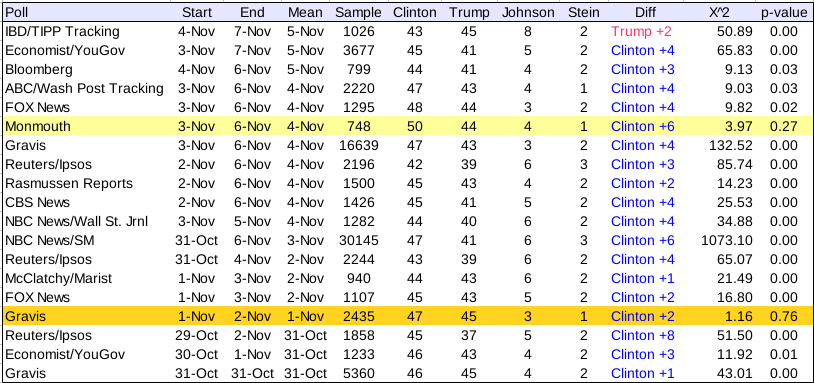
The best poll was by Gravis on 1-2 Nov. A later Gravis poll taken 3-6 Nov was actually one of the worst polls.
We see that, looking at a four-way race, the pollsters did not do that well. Only two of 19 polls did the results not differ significantly from the actual four-candidate distribution.
But what if we only consider the races that matter—Clinton and Trump? I’ve taken the four-way races and turned them into 2-way races. Mathematically, when doing the test, I “normalize” the results so that the sum of Clinton and Trump percentages are now 100%.
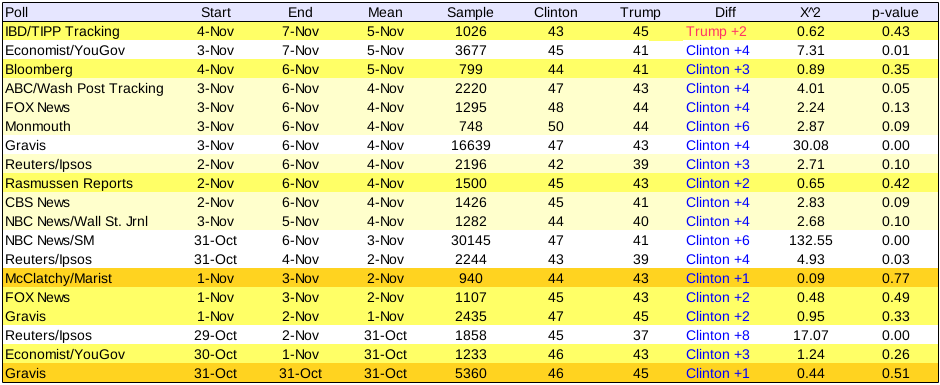
We see that for 14 of the 19 polls, the results did not differ from the actual outcome. Again, the worst poll, by far, was the NBC News/Survey Monkey online tracking poll. With such a large sample, they should have been much closer than they ended up being.
So, whatever you’ve heard, the national polls were generally not that far off in predicting two outcomes of the popular vote: The winner of Clinton v. Trump, and the relative proportions of Clinton v. Trump votes.

In this case, it might be appropriate to refer to NPR’s program by the label applied to it by Rush Limbaugh years ago: “All Things Distorted”.
Of course it’s a misuse of polls to rely on them as to predict the outcome of a political race. Otherwise gamblers would use them at the horse races. Which are always more fun when someone other than the best horse and/or the best jockey who are the favorites win. I think some pollsters are in trouble as the results fell outside of the vig.